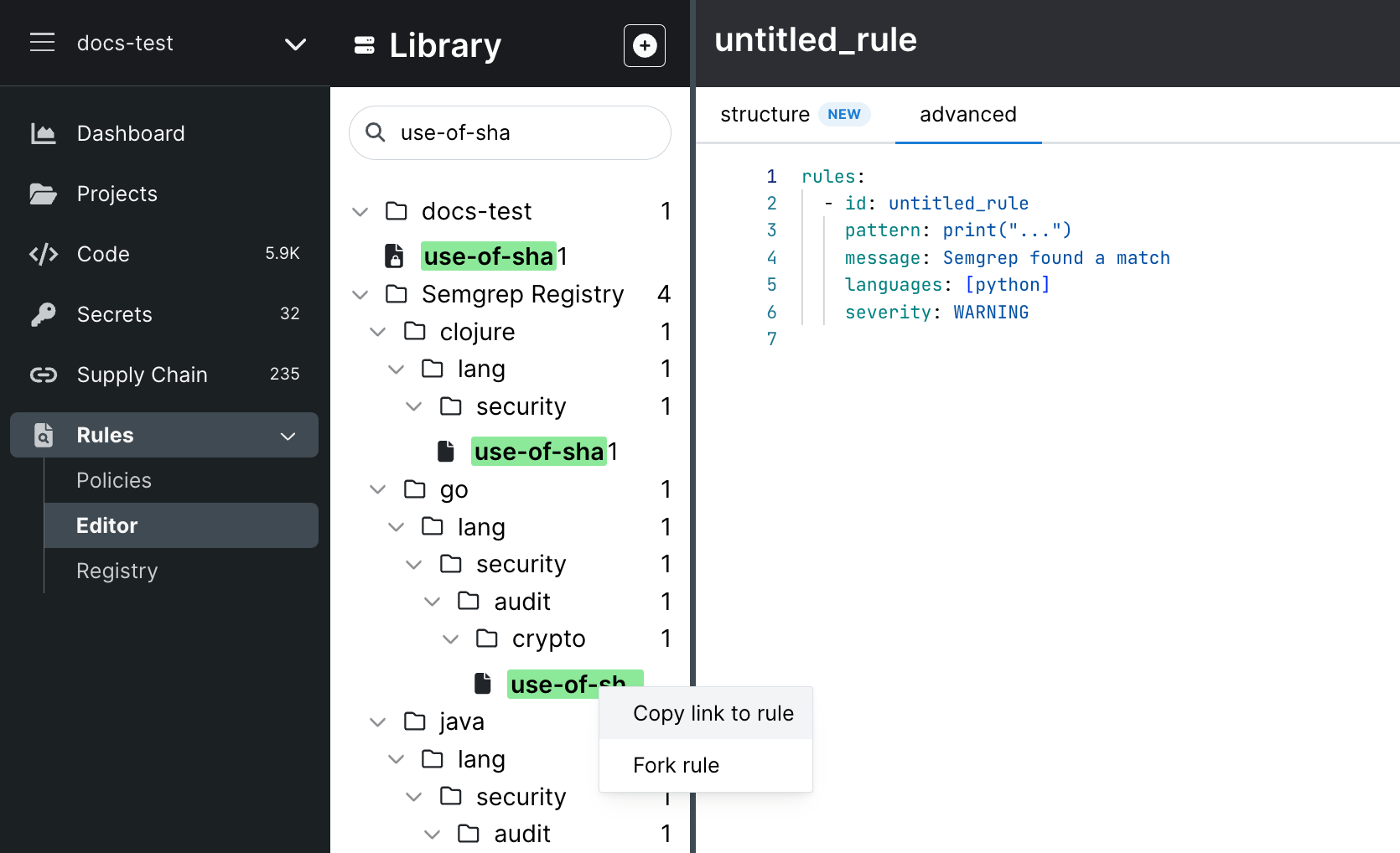
In this post, I will show you how to set up Semgrep for your project, give examples of common code issues that it can detect, and provide best practices for using Semgrep in code review. By the end, you will have a better understanding of how Semgrep can improve your